As part of a project led by the Institute for Research in Schools (IRIS), I spent time classifying stars using their spectra recorded by the Spitzer space telescope. My group classified the features of each spectrum before deciding on the type of star we believed it to be. However, I noticed several issues with this approach.
- Firstly, classifying the spectra took a long time, and we were significantly limited by the time we had available.
- Secondly, spectra could be classified differently depending on who classified them in our group, and the specific prior experiences of that individual. In other words, the classifications were subjective.
- Finally, there was no easy way to identify errors in our classifications, except by classifying the spectra all over again.
To fix these issues, I decided to explore the possibility of automating the classification process by using machine learning.

Machine learning requires a dataset to learn from, so I exported data from over 100 spectra our group had classified. This dataset included features as well as final classification. I initially tried to build a neural network mapping directly from spectrum to classification, but this proved to be too difficult to learn directly. Instead, I broke the process into sub-problems, much like how humans classify spectra.
I built up a total of 9 neural networks using the Tensorflow library (python). 8 networks looked for different features in the spectra, whilst one final network performed the overall classification. Splitting the process into these steps improved accuracy significantly because each network could be fine-tuned to perform its specific task as well as possible.
I wasn’t done yet, however. By tuning the hyper-parameters of each network, I managed to improve accuracies even further. Crucial to this was determining the optimal pre-processing technique for each network. Spectra can be of different lengths, and in any case, are much too long to input into the networks directly. So, I developed a pipeline to normalise spectra, turn them into discrete data points and optimise them for feature classification.
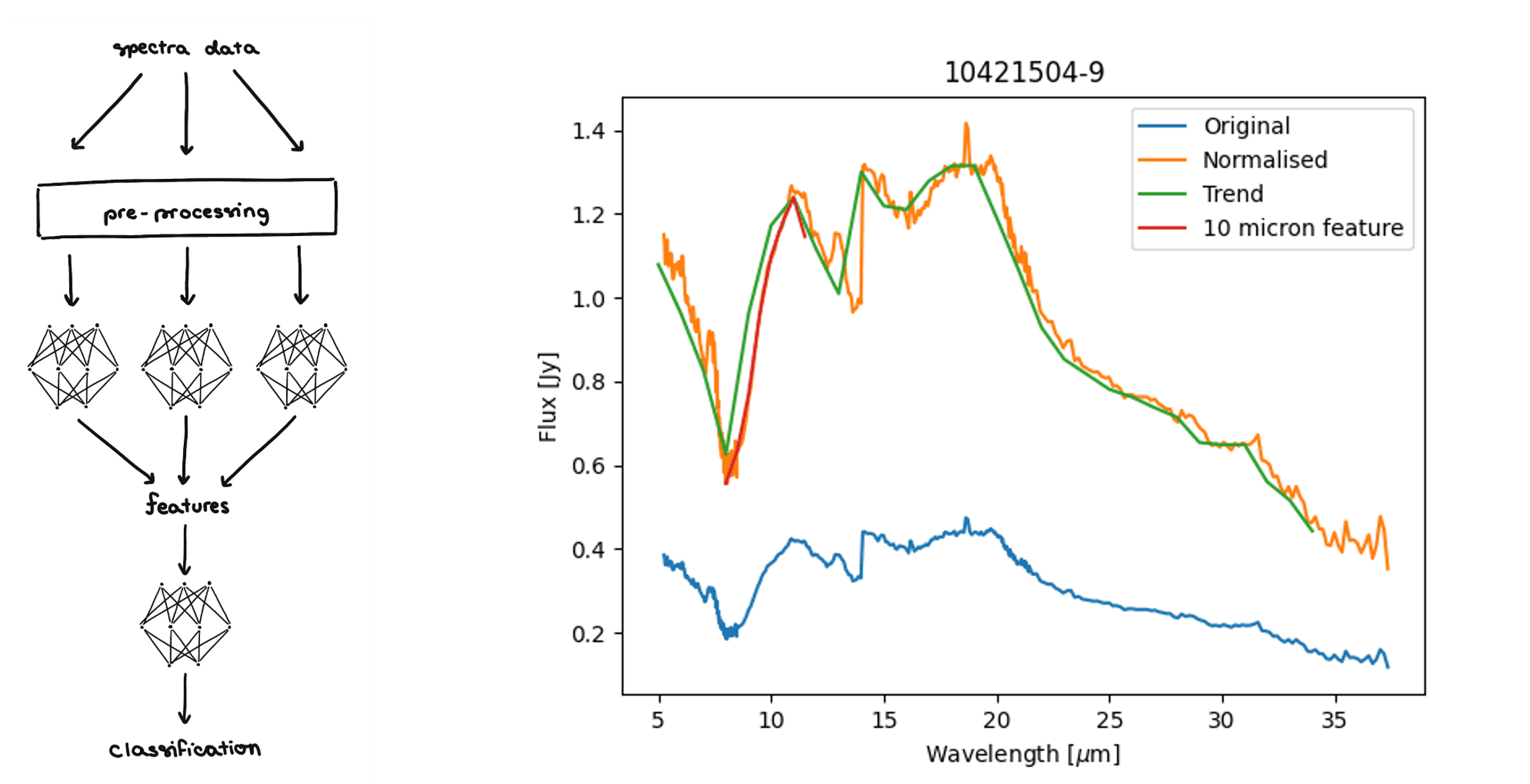
Firstly, data points are transformed into percentages of their median flux. Then they are quantised. For example, before classifying the trend, the spectrum is broken into 30 data points, each of which takes the median flux value in its one-micron bracket. Or, when classifying absorption features, smaller brackets would be used and the minimum or maximum flux in each bracket would be taken instead.
As well as needing to be pre-processed, there was an issue of bias in the system, towards or against certain classifications. For example, there were very few dipping or flat spectra in my dataset as most were rising or falling, which resulted in the system almost never correctly classifying a dipping spectrum. To alleviate this issue, I oversampled the spectra when forming a training database to ensure a roughly equal proportion of each classification. To create enough spectra for this to occur, each was subtly mutated if added multiple times. This shifted and stretched the spectrum to create what, to the computer, appeared like a completely new spectrum. This helped build the resilience of the system against all possible inputs, despite the database size.
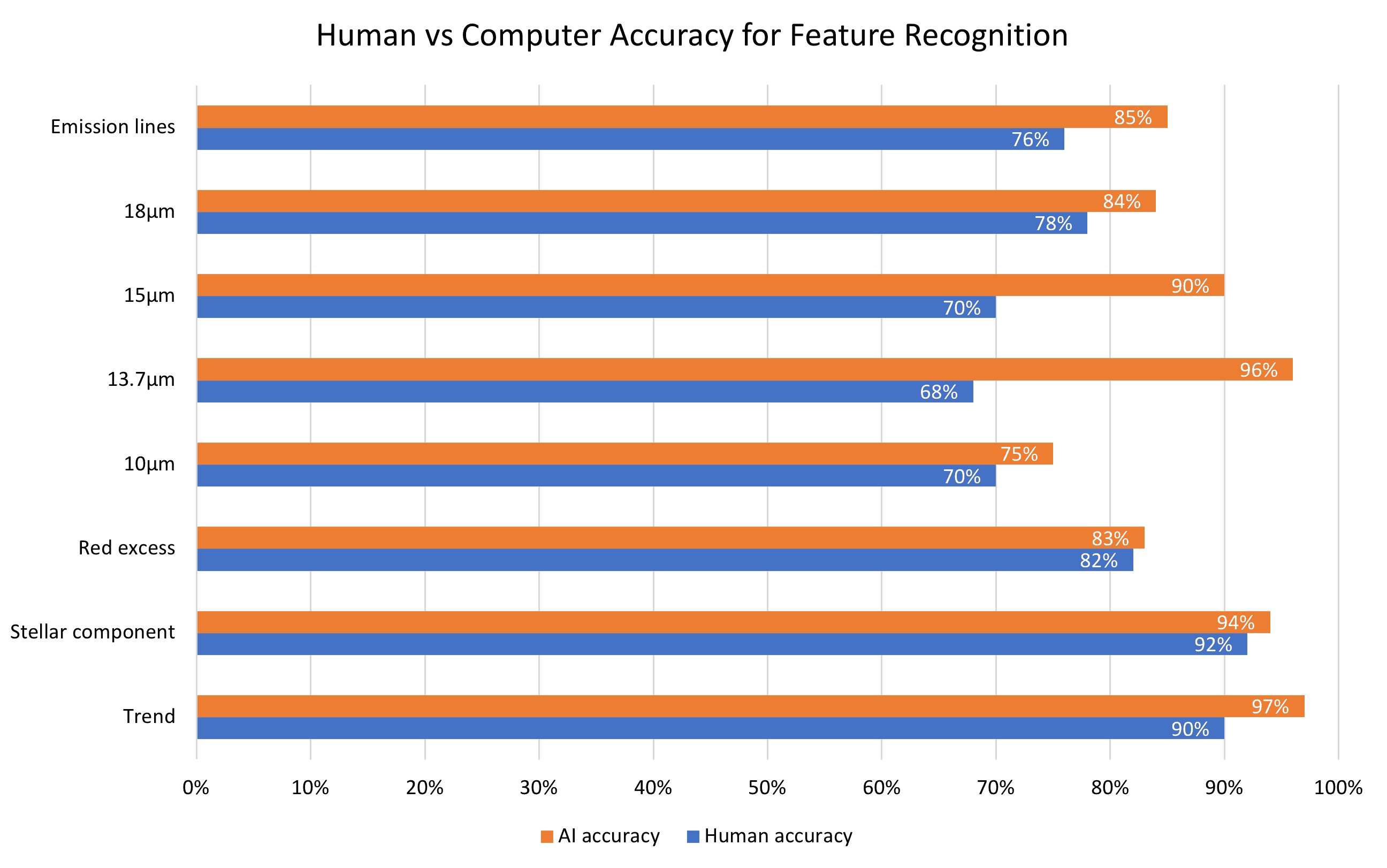
When evaluated on a testing dataset, the model exceeded the performance of our school group on feature classification – even when the dozen or so of us were working together! The orange bars in the graph indicate the accuracy of my machine learning model on a test dataset, whereas the blue bars indicate the accuracy of our group on the final training exercise.
The next step, of course, was to classify the type of star using these features. By encoding these classifications as binary flags, the features can be input into a final neural network that has learned the mapping from features to the type of star.
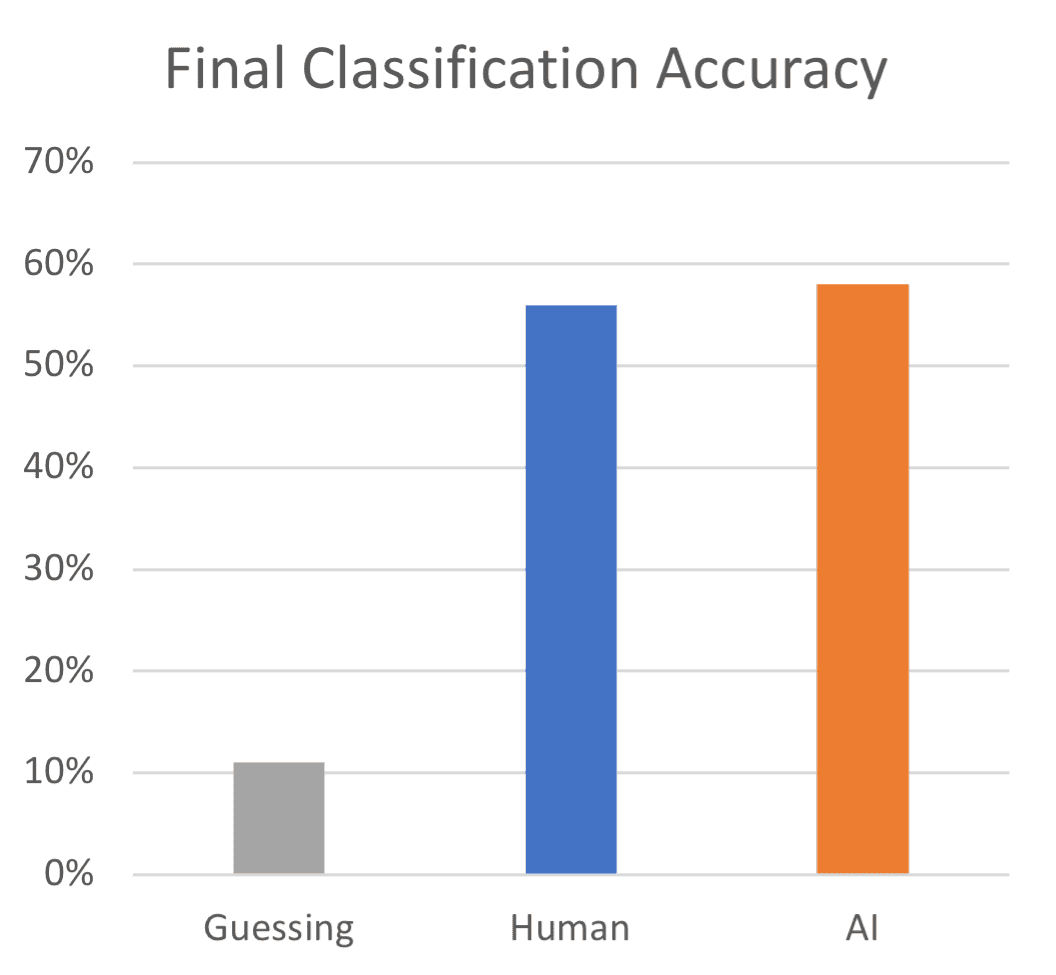
This graph shows the performance – it just beats human classification by 2 percentage points. One problem this neural network faces is errors in the previous networks. If just one feature is misclassified, the final classification can be thrown completely.
In time, I hope this accuracy can be improved with a larger dataset – I believe the small number of examples available to learn from is limiting the potential of the model.
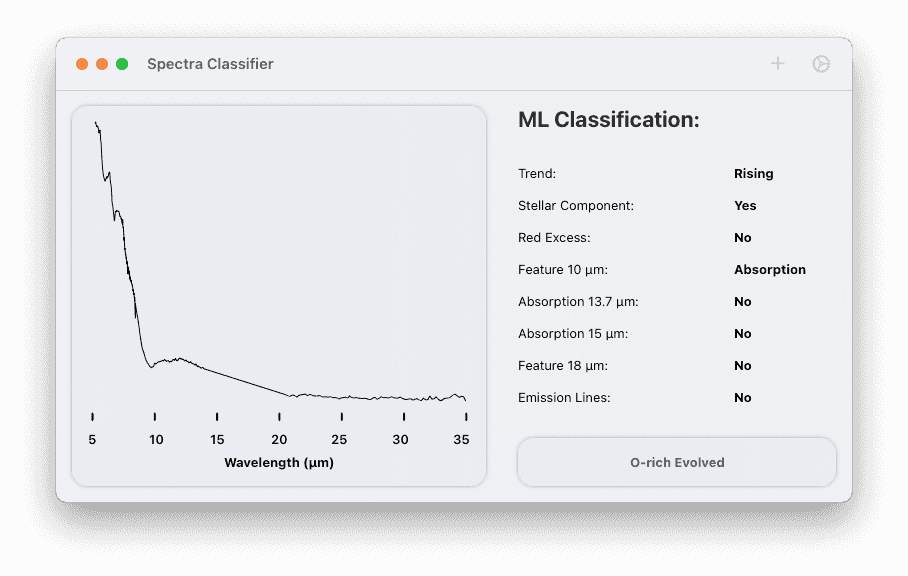
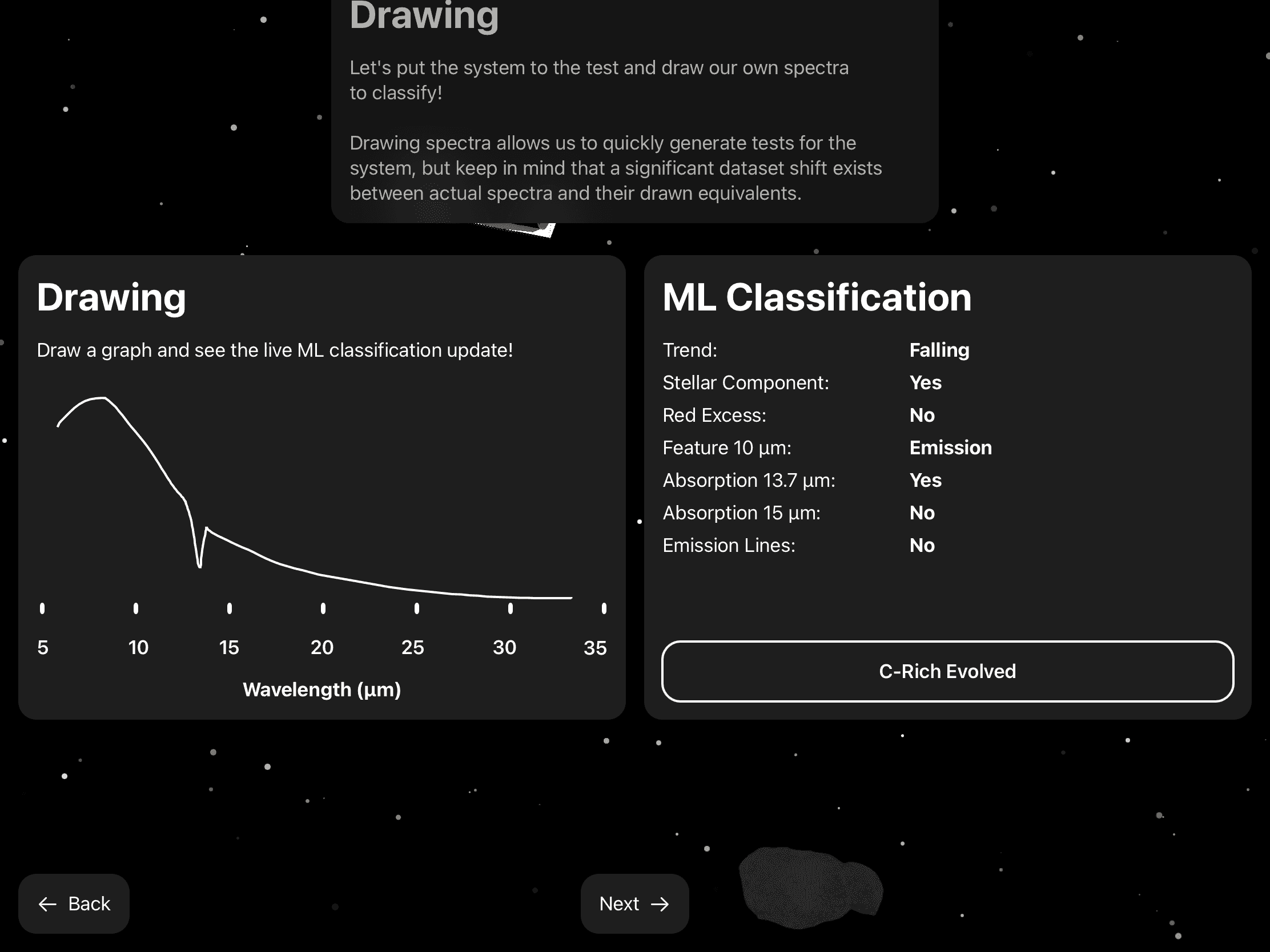
Using the models developed above, I built a small macOS application to assist in classifying spectra. This allows the students in my original group to check their classifications quickly.
Additionally, I used this research as the basis for my entry in Apple's WWDC Swift Student Challenge (2022) which was selected as a winning entry. The application (built using Swift) explains to the user the concept of stellar classification, and allows them to classify their own spectra with the model by drawing them on screen with the Apple pencil.